
Начало относительно широкого использования возможностей электротехники (а в дальнейшем и электроники) в музыке относится к середине 30-х годов XX века. В этот период Л. Хаммонд запатентовал электрический орган, представлявший собой набор электромеханических генераторов, каждый из которых вырабатывал колебания с частотой, соответствующей частоте одной из нот. Для исполнителя же, в конечном счете, самым важным в этом инструменте было то, что управление органом Хаммонда осуществлялось с помощью привычной органной клавиатуры. В те времена от такого электрического инструмента требовалось, в основном, чтобы его звучание было максимально похоже на звучание старшего брата — духового органа.
Синтезаторы
В процессе бурного развития электроники
совершенствовались методы и устройства генерации и обработки звуковых
колебаний в электронных органах и в подобных им электронных музыкальных
инструментах. Все больше внимания уделялось вопросам темброобразования
как для более точной имитации звучания традиционных инструментов, так и
в целях получения новых, необычных тембров. Основным методом
темброобразования оставался аддитивный (от английского "additive")
метод, применявшийся еще в органе Хаммонда. Этот метод заключается в
том, что результирующий тембр формируется путем сложения нескольких
исходных колебаний.
При использовании в качестве исходных
колебаний синусоидальных сигналов с кратными (отличающимися в целое
число раз) частотами и регулируемыми амплитудами отдельных составляющих
можно получить большое количество самых разнообразных тембров. Такая
разновидность аддитивного метода называется гармоническим синтезом
тембра.
Другой разновидностью аддитивного метода является
регистровый синтез. В этом случае в качестве исходных используют
колебания более сложной формы, например, пилообразные или
прямоугольные.
И в том, и в другом случаях для точного
воспроизведения звучания заданного музыкального инструмента требуется
очень большое (теоретически бесконечно большое) число исходных
колебаний. Чем меньше исходных колебаний, тем сильнее отличается
синтезированный звук от звучания имитируемого инструмента. На практике
оказывается, что даже при полутора-двух десятках исходных колебаний
звучание синтезатора лишь в основном напоминает то, что хотелось
получить. И здесь, как это часто случается, на помощь технике приходит
сам человек. Наша психика устроена так, что если нами будут опознаны
хоть какие-нибудь характерные признаки знакомого музыкального
инструмента, то в сознании произойдет подмена фактического звучания на
воображаемое и на проявляющиеся в дальнейшем огрехи имитации
реагировать мы будем значительно слабее, чем они того заслуживают.
Но (даже с учетом этого нашего замечательного свойства) проблема
формирования большого числа исходных сигналов остается актуальной. Ее
решение значительно упростилось с появлением и развитием цифровых
устройств, работающих с сигналами, имеющими прямоугольную форму.
Реализация этих устройств в виде интегральных микросхем практически
сняла ограничение на количество исходных сигналов. А потом наступило
время, когда гармонический синтез, реализуемый довольно громоздкими и
дорогостоящими устройствами, не выдержал конкуренции со стороны
регистрового синтеза и был вытеснен последним.
Наряду с
рассмотренным аддитивным методом, в синтезаторах широко применяется и
субтрактивный метод (от английского "subtractive" — вычитание).
Сущность этого метода заключается в том, что новый тембр создается
путем изменения соотношений между отдельными составляющими в спектре
первоначального колебания. Реализуется этот метод как бы в два этапа.
Сначала формируются колебания, основные частоты которых соответствуют
частотам нот. Главное требование к первоначальному колебанию сводится к
тому, что оно должно иметь как можно более богато развитый тембр (иметь
большое количество спектральных составляющих). На втором этапе с
помощью частотных фильтров из первоначального колебания выделяют
частотные составляющие, характерные для имитируемого музыкального
инструмента. Этот метод также удобно реализовать на базе
быстродействующих цифровых интегральных микросхем. В теории сигналов
давно доказано (и экспериментально подтверждено), что спектр импульсной
последовательности тем шире, чем короче каждый импульс. Поэтому
первоначальными сигналами могут служить последовательности коротких
прямоугольных импульсов.
Таким образом, при синтезе звуков в
электронных музыкальных инструментах аддитивный и субтрактивный методы
мирно уживаются и дополняют друг друга.
Развитие электронных
музыкальных инструментов стимулировало создание электронных музыкальных
синтезаторов. В синтезаторах, с одной стороны, нашли свое дальнейшее
развитие ранее применявшиеся методы синтеза звука, с другой стороны,
были внедрены и принципиально новые методы. Однако не это составляет
основное отличие синтезаторов. Главное заключается в том, что за счет
использования микропроцессоров для управления синтезом звуков в них
имеется возможность быстрого и очень просто выполняемого перехода от
одного имитируемого (или синтезируемого) инструмента к другому. И еще
одно отличие: за счет применения запоминающих устройств большого объема
имеется возможность хранения и постоянного дополнения гигантского
количества алгоритмов синтеза звуков. Переход от одного синтезируемого
инструмента к другому происходит за время, значительно меньшее, чем
длительность самой короткой ноты. На практике это означает, что, в
принципе, каждую очередную ноту синтезатор может сыграть другим тембром
(инструментом). Кроме того, в состав синтезатора входят несколько
идентичных блоков синтеза, поэтому и одновременно взятые ноты могут
быть исполнены как бы различными музыкальными инструментами.
Не
сразу синтезаторы стали такими совершенными. Первые электронные
синтезаторы звуков скорее представляли собой специализированные, причем
аналоговые, а не цифровые, вычислительные машины. Из-за сложности и
недостаточной оперативности управления они были предназначены, в
основном, не для исполнительских целей, а для экспериментов, проводимых
в интересах совершенствования электронных музыкальных инструментов,
создания звуковых эффектов для озвучивания кинофильмов и исследований в
области электроакустики.
Развитие технологии аналоговых
интегральных микросхем позволило со временем реализовать отработанные
методы синтеза в сравнительно доступных как в отношении управляемости,
так и в отношении стоимости исполнительских инструментах. Приоритет в
этой области принадлежит Р. Мугу, выпустившему в 1964 году первый такой
синтезатор. Его основой стал генератор, управляемый напряжением,
который способен формировать сигналы прямоугольной, пилообразной и
синусоидальной формы. Различные варианты соединения таких генераторов и
сложения их выходных сигналов позволили получить обширную палитру новых
"электронных" звуков. Такой метод синтеза получил название:
"FM-аддитивный метод". Метод основан на частотной модуляции: изменении
частоты сигнала в соответствии с законом изменения некоторого
управляющего напряжения. Со временем было накоплено большое количество
таких алгоритмов управления частотами генераторов Муга, которые
представляли ценность в музыкальном отношении, и поэтому закладывались
в блоки управления новых синтезаторов.
В результате развития
цифровой техники произошел естественный переход от аналоговых к
цифровым формирователям колебаний, способным генерировать сигналы
произвольной формы. Сами формирователи могут быть реализованы как
аппаратно, так и программно, а форма генерируемого сигнала в виде
цифрового алгоритма управления формирователями хранится в запоминающем
устройстве. Возможность использования большого числа формирователей
(порядка нескольких десятков), которые имеют независимое управление
частотой колебаний и огибающей амплитуды (размаха колебаний) сигналов,
для синтеза каждого голоса музыкального инструмента позволила говорить
о переходе на качественно новый по сравнению с аналоговыми
синтезаторами уровень. Описанный принцип синтеза звуков с некоторыми
модернизациями применяется и в синтезаторах звуковых карт. Кроме того,
синтезаторы большей части звуковых карт устроены проще и, в связи с
этим, обладают меньшими возможностями по сравнению с "начинкой"
электронных музыкальных синтезаторов.
Итак, при FM-методе синтез
звука с необходимым тембром производится на основе использования
нескольких генераторов звуковых частот при их взаимной модуляции.
Совокупность генератора и схемы, управляющей этим генератором, принято
называть оператором. Схема соединения операторов и параметры каждого
оператора (частота, амплитуда и закон их изменения во времени)
определяют тембр звучания. Количество операторов определяет
максимальное число синтезируемых тембров. В звуковых картах
используется как двухоператорный, так и четырехоператорный синтез.
Виртуальные синтезаторы позволяют реализовать значительно более сложные
алгоритмы синтеза.
В операторе следует выделять два структурных
элемента: частотный модулятор и генератор огибающей. Частотный
модулятор определяет высоту тона, а генератор огибающей определяет
относительно медленное изменение амплитуды колебания во времени и, тем
самым, тембр звука. Звуковые колебания, формируемые различными
музыкальными инструментами, имеют различные огибающие. Однако любую
огибающую можно условно расчленить на несколько характерных фаз,
которые принято называть: attack (атака), decay (спад), sustain
(поддержка), release (освобождение). Пояснением сказанного служит рис.
1.11.
Например, при нажатии на клавишу фортепиано, действительно,
сначала амплитуда колебаний быстро возрастает до максимального
значения, затем несколько спадает, потом в течение некоторого времени
остается практически постоянной и, наконец, колебания медленно
затухают.
В более совершенных синтезаторах элементарный процесс
извлечения звука состоит не из четырех, а из шести фаз (рис. 1.12). Это
позволяет получить большее сходство синтезируемого звучания и его
естественного образца.
Неоспоримое достоинство FM-синтеза состоит
в том, что на его основе можно получить несчетное количество
"электронных" тембров. Немаловажно также то обстоятельство, что не
требуется заранее записывать и хранить в памяти синтезируемые звуки.
Достаточно хранить алгоритм их синтеза.

Рис. 1.11. Четыре фазы огибающей сигнала

Рис. 1.12. Шесть фаз огибающей сигнала
Метод частотно-модуляционного синтеза развивается и широко
используется. Накоплено большое количество алгоритмов синтеза
оригинальных звучаний. В принципе, как мы уже и говорили, для этого
метода нет невозможного.
Вопрос заключается только в том, ценой
каких аппаратурных затрат достигается желаемый результат. Но, в
соответствии с законами развития, сильная сторона метода со временем
превратилась в свою противоположность. Сила метода состоит в том, что
любой звук может быть получен модуляцией частоты генератора. Слабость
метода заключается в том, что для синтеза любого звучания используется
только генератор и только его частотная модуляция, причем процесс
синтеза во времени совмещен с процессом исполнения музыки. Почти одно и
то же заключено в этих двух фразах — да не совсем. Выходит, что
возможности синтеза ограничиваются не только сложностью аппаратурной
реализации, но и сложностью алгоритма управления синтезатором в
реальном времени. Поясним эту мысль. Для точного воспроизведения
звучания какого-то традиционного музыкального инструмента, во-первых,
требуется значительное число модулируемых генераторов. Во-вторых,
управлять их частотой следует по очень сложному алгоритму, ибо только
таковой в состоянии учесть малейшие оттенки звучания, присущие именно
данному инструменту. Например, концертный рояль воспроизводит около 4,5
тысяч различимых на слух тембров. Алгоритм должен успевать считываться,
вычисляться и передаваться, словом, выполняться компьютером. А
генераторы должны успевать его отрабатывать. Поэтому качество синтеза
ограничивается также и быстродействием компьютера.
Технические
возможности микропроцессорной системы управления не в такой степени
сказывались бы на качестве звука, если бы его синтез производился не в
реальном времени, а заранее, если бы результаты синтеза сохранялись и
использовались при исполнении музыки. Правда, тогда пришлось бы
отказаться и от привычного FM-синтезатора. Так оно, в общем, и
произошло.
Сэмплеры
В конце семидесятых годов прошлого века был создан
цифровой музыкальный инструмент, в котором реализован принципиально
иной подход к синтезу музыки, получивший название "sampling". Буквально
это слово означает отбор образцов. Суть этого способа состоит в том,
что для синтеза звука используются сгенерированные не в реальном
времени, а заранее фрагменты, хранящиеся в памяти инструмента. В
частности (и чаще всего), эти фрагменты могут быть получены путем
записи в цифровой форме натуральных звуков. Синтезаторы, в которых
воплощен такой принцип, называются сэмплерами, а образцы звучания
— сэмплами. Процесс записи сэмплов принято называть оцифровкой
или сэмплированием. В целях экономии необходимой памяти сэмплы могут
храниться в виде нескольких фрагментов: фрагмента начала звука,
фрагмента стационарной фазы и фрагмента завершения звука. Фазы начала и
завершения звука (вспомним рис. 1.11) при исполнении воспроизводятся
без изменений, а стационарная фаза "зацикливается" на время нажатия
клавиши.
Конечно же, сэмплы, записанные с помощью микрофонов,
расположенных, например, вблизи рояля, до того, как оказаться в памяти
синтезатора, подвергаются нескольким процедурам обработки. Запись
очищают от посторонних звуков, подчеркивают стереоэффект и производят
частотную коррекцию. В принципе существуют и аппаратура, и программное
обеспечение, позволяющие отредактировать заготовку сэмпла, а то и вовсе
сконструировать звучание по своему усмотрению.
Для одного и того
же инструмента могут быть записаны сэмплы, относящиеся к различным
приемам игры и соответствующие различной динамике звукоизвлечения,
например: игра на рояле с использованием педали — и без нее,
сильный удар по клавише — и мягкое касание. При воспроизведении
различные динамические оттенки исполнения получают комбинированием этих
сэмплов в различной пропорции.
У рассматриваемого метода есть еще
и другое название — волновой синтез. Закодированные наборы
образцов хранимых звуков называют волновыми таблицами (Wave Table). О
звуковых картах, реализующих рассматриваемый метод синтеза, говорят,
что они поддерживают режим Wave Table (WT).
Одна из основных
проблем волнового синтеза состоит в том, что для хранения голосов
инструментов требуется запоминающее устройство очень большого объема.
Если бы задача решалась "в лоб", т. е. запоминалось бы звучание каждой
ноты инструмента, то проблема, скорее всего, и по сей день оставалась
бы неразрешимой. Значительного сокращения необходимой памяти достигают
за счет того, что запоминается звучание немногих нот (в пределе —
одной). Формирование звучания остальных нот происходит путем изменения
скорости воспроизведения сэмпла в той степени, каково отношение частоты
извлекаемой ноты к частоте ноты, хранящейся в памяти.
Как с
помощью одного музыкального тона синтезатор получает другой? Допустим,
исходный сэмпл оцифрован на частоте 44,1 кГц. Теперь, если мы будем
воспроизводить его на удвоенной частоте дискретизации 88,2 кГц, т. е.
вдвое быстрее, высота звука возрастет на октаву. Если же воспроизводить
сигнал на пониженной частоте дискретизации, то высота звука
соответственно уменьшится. Таким образом, если воспроизводить сэмпл на
измененной соответствующим образом частоте дискретизации, в принципе
можно получить звук любой высоты.
Однако такой подход содержит
неприятный момент. Одновременно со смещением величины тактовой частоты
и высоты звука будет изменяться длительность атаки и скорость затухания
сигнала. Так, если мы удвоим тактовую частоту, то наряду с удвоением
высоты звука в два раза уменьшится общее время звучания сигнала (так
как он будет проигрываться в два раза быстрее). Отсюда вдвое сократится
длительность атаки, и вдвое возрастет скорость затухания звука. Это
вызовет искажение общего впечатления о звуке. Тембр воспроизводимого
сигнала заденут и более серьезные изменения.
В реальном
музыкальном инструменте при изменении высоты звука форма
амплитудно-частотной характеристики (АЧХ) излучающих звук поверхностей,
местоположение на оси частот, величина ее максимумов и провалов
механических и акустических резонансов обычно не изменяются. А вот при
изменении скорости воспроизведения оцифрованного сигнала вместе с
частотой основного тона изменится и форма АЧХ (растянется или сожмется,
максимумы и минимумы сместятся по оси частот). Конечно, это сильно
исказит звук. Кроме того, в некоторых музыкальных инструментах
(пианино, гитара и т. д.) звуки разной частоты формируются с помощью
различающихся механически элементов конструкции (струны с оплеткой и
без нее; несколько струн, настроенных в унисон). В этом случае звук,
полученный с помощью удвоения скорости воспроизведения оцифрованного
сигнала, может изначально не соответствовать реальному на октаву более
высокому звуку.
Поэтому в WT-синтезаторах применяется несколько
другой способ изменения высоты звука. Оцифровывается несколько разных
по высоте сигналов (сэмплов) реального музыкального инструмента,
перекрывающих весь его частотный диапазон. Шаг по частоте должен быть
достаточно мал, чтобы изменения тембра, связанные с конструктивными
особенностями инструмента, при смещении частоты основного тона с
помощью варьирования частоты дискретизации не были заметны на слух.
В недорогих устройствах считается достаточной оцифровка через половину
октавы. При генерации звука определенной высоты WT-синтезатор
определяет, в каком частотном диапазоне находится звук, и использует
соответствующие сэмплы из своей таблицы, корректируя их частоту
основного тона точно до требуемой высоты, виртуально подстраивая
частоту дискретизации. Под виртуальностью подразумевается следующее.
Частота дискретизации выходного сигнала жестко стабилизирована
кварцевым генератором (например, 44,1 кГц). Звук музыкального
инструмента также дискредитирован на частоте 44,1 кГц. Для изменения
высоты тона надо выбирать отсчеты сигнала из таблицы с частотой,
немного отличной от 44,1 кГц, а подавать на ЦАП с частотой, точно
равной 44,1 кГц. Это полностью аналогично изменению частоты
дискретизации данных и, естественно, будет восприниматься слухом как
изменение высоты основного тона сигнала.
Кроме того, синтез
звучания некоторых музыкальных инструментов становится более
реалистичным и выразительным при одновременном воспроизведении
нескольких сэмплов. То есть звук инструмента может генерироваться
WT-синтезатором путем наложения звучания нескольких сэмплов.
С
помощью специальных программ-редакторов можно изменить
(подкор-ректировать) содержание любого произвольного слоя, изменяя
форму волны, высоту тона сэмпла, включить использование обычных или
управляемых генераторами фильтров и т. д. Таким образом можно добиться
самого необычного звучания.
Поскольку качество звучания звуковой
карты с WT-синтезатором напрямую зависит от качества звучания образцов
инструментов, хранящихся в памяти карты, желательно иметь сэмплы
высокого качества (с высоким разрешением записи), что в свою очередь
приводит к росту объема банка инструментов.
Для гипотетического
устройства, имеющего диапазон частот генерируемого звука в пять октав,
при оцифровке через интервал в один тон по высоте с частотой
дискретизации 48 кГц и разрядностью данных 24 бита понадобится около 7
Мбайт 1-секундных отрезков сигнала реального музыкального инструмента.
Однако WT-синтезаторы некоторых звуковых карт имеют меньший объем
памяти, хотя могут имитировать более ста инструментов. Достигается это
несколькими методами. Звук оцифровывается с большим шагом по частоте
основного тона и подвергается различным видам компрессии. В таблице
хранятся отрезки сигнала значительно меньшей по времени длины, чем одна
секунда. При этом для синтеза длительных нот применяется зацикливание
(многократное повторное воспроизведение отрезка сигнала). Отрезок как
бы превращается в кольцо. Естественно, для гладкого, без щелчков на
стыке кольца требуется специальная обработка отрезка сигнала. Он должен
содержать целое число периодов основного тона, а отсчеты около стыка
должны быть обработаны специальной сглаживающей программой.
Патчи
для инструментов с малой длительностью звучания (ударных) обычно
записываются полностью, а для остальных может записываться лишь начало,
конец звука и небольшая "средняя" часть, которая затем проигрывается в
цикле в течение нужного времени.
В процессе воспроизведения звука
специальный процессор выполняет операции над патчами, изменяя их
амплитуду, частоту и таким образом формируя звук требуемой громкости,
полностью соответствующий необходимому тембру.
Безусловным
достоинством синтеза на основе таблицы волн является предельная
реалистичность звучания классических инструментов и простота получения
звука.
Основой "голоса" WT-синтезатора является цифровой звук. В
этом и заключается самое главное отличие WT- от FM-синтезаторов, у
которых "голосовыми связками" являются генераторы аналоговых колебаний
строго определенных форм. В принципе, используя FM-синтез, можно
получить очень большое количество тембров. Однако на основе одной и той
же волновой формы при использовании WT-синтезатора можно получить еще
большее количество тембров (а ведь количество сэмплов ограничивается
только объемом памяти). Все дело в том, что WT-синтезатор — это
не просто "маленький цифровой магнитофончик", который может в цикле и с
разной скоростью (а значит и в различной тональности) воспроизводить
свою фонограмму — сэмпл. Кроме этого он может проделывать самые
разные операции над генерируемым звуком: пропускать его через
резонансный фильтр,
модулировать его как по амплитуде, так и по частоте, накладывать различные эффекты...
Для того чтобы в дальнейшем понимать смысл действий по редактированию
музыки, необходимо познакомиться с архитектурой звукового элемента
типичного синтезатора. Звуковой элемент — это некоторый
аппаратным путем реализованный блок полифонического синтезатора,
который воспроизводит звучание только одного голоса. Слово
"полифонический" означает, что у синтезатора таких блоков много и
каждый из них в определенный момент времени занимается генерацией
только одного звука. Когда вы берете аккорд на MIDI-клавиатуре, не
подозревая того, вы запускаете в работу столько звуковых элементов,
сколько нот в аккорде, а в некоторых случаях и больше. Вариант
структурной схемы типичного звукового элемента показан на рис. 1.13.
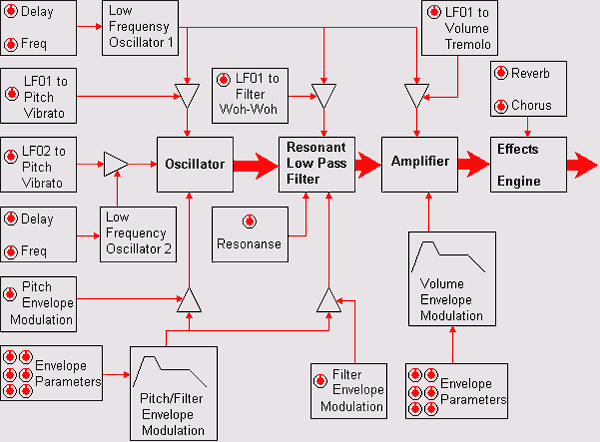
Рис. 1.13. Структурная схема типичного звукового элемента
Сразу отметим, что все преобразования над сэмплом происходят в цифровом
виде. Какие же именно преобразования претерпевает сэмпл, прежде чем
попасть на выход синтезатора?
Сердце звукового элемента —
осциллятор (oscillator) — тот самый воображаемый цифровой
магнитофончик, о котором мы говорили совсем недавно.
Это
устройство воспроизводит сэмпл с заданной скоростью. Скорость
воспроизведения зависит от номера нажатой MIDI-клавиши. Кроме того,
этот "магнитофончик" может воспроизводить звук в цикле: "докрутил" звук
до отметки конца цикла и быстро перескочил к метке начала цикла (и так
— по кругу). А можно сделать так, чтобы, как только вы отпускаете
MIDI-клавишу, "магнитофончик" выходил из цикла и начинал воспроизводить
все фазы сэмпла подряд, пока сэмпл не закончится.
С осциллятора
цифровая информация о звуке попадает на резонансный НЧ-фильтр (Resonant
Low Pass Filter), с помощью которого можно изменять спектр сэмпла,
получая при этом очень интересные эффекты, например, эффект, называемый
"Wah-wah" ("Вау-вау"). Частотная характеристика фильтра определяется
двумя параметрами: частотой среза (Filter Cutoff) и коэффициентом
усиления фильтра на частоте среза (Resonance). Последний из параметров
часто обозначается как Filter Q.
После фильтра звук попадает на
усилитель (Amplifier), где ему придается заданная в пространстве
"громкость-время" форма — амплитудная огибающая.
Теперь
звук почти готов к употреблению. Остается пропустить его некоторую
часть через эффект-процессор (Effects Engine), чтобы реализовать
эффекты реверберации и хоруса (Reverb, Chorus). Наверное, требуется
пояснить, что значит "некоторая часть звука". Звуковой сигнал следует
двумя путями: первый путь ведет сразу в обход эффект-процессора, а
второй — через эффект-процессор. На первом пути звук не
претерпевает никаких изменений. Проходя же по второму пути, звук,
например, полностью превращается в свое эхо. Затем эти пути вновь
сходятся: исходный звук смешивается со своим эхом. Очевидно, что
регулировать глубину эффектов можно, изменяя уровень сигнала,
следующего вторым путем.
Теперь звук полностью готов к
употреблению и поступает на ЦАП синтезатора, а затем или на микшер
звуковой карты, или непосредственно на цифровой выход в стандарте
S/PDIF, если таковой имеется у данной звуковой карты.
Кроме
рассмотренных блоков, в которых происходит генерация и преобразование
звукового сигнала, обычно существуют еще вспомогательные генераторы,
создающие низкочастотные колебания (Low Frequency Oscillator). На схеме
в качестве примера показаны два таких генератора: LFO1 и LFO2.
Низкочастотные колебания требуются для реализации эффектов частотной
(частотное вибрато) и амплитудной (амплитудное вибрато, тремоло)
модуляции, а также тембрового вибрато (эффекта "Вау-вау"). Для каждого
из генераторов регулируется два параметра: Delay — задержка
начала низкочастотной генерации от момента начала звучания сэмпла, Freq
— частота колебаний.
Генераторы огибающих Pitch/Filter и
Volume Envelope Modulation предназначены для управления высотой тона
(Pitch), параметрами фильтра (Filter) и громкостью (Volume)
непосредственно в процессе воспроизведения сэмпла.
В отличие от
традиционного четырехфазного представления звуков ADSR (аббревиатура от
Attack, Decay, Sustain, Release) в рассматриваемом гипотетическом
синтезаторе звук делится на шесть фаз (DAHDSR): Delay (задержка),
Attack (атака), Hold (удержание), Decay (спад), Sustain (поддержка) и
Release (освобождение). Именно по этой причине на блоке Envelope
Parameters (параметры огибающей) изображено шесть регуляторов, каждый
из которых символизирует возможность управления определенной фазой
звука. Перечисленные фазы показаны на рис. 1.12.
Кроме основных
блоков, на структурной схеме символически показаны манипуляторы (ручки,
при помощи которых можно регулировать тот или иной параметр звукового
элемента). Конечно же, никаких ручек физически не существует, все
настройки — это числа, которые хранятся в памяти драйвера,
обслуживающего синтезатор.
Треугольниками обозначены модуляторы.
Для того чтобы вы лучше поняли их назначение, приведем пример из
повседневной жизни. Все пользуются водопроводным краном. В кране течет
вода. Интенсивность ее протекания (если можно так выразится)
характеризуется положением ручки крана. А теперь проведем аналогию
между водопроводным краном и модулятором в схеме синтезатора: кран
— модулятор, вода — исходный сигнал (например,
низкочастотные колебания от LFO1), ручка — модулирующий сигнал
(например, LFO1 to Pitch), положение ручки — параметр
регулировки, т. е. просто число, характеризующее глубину модуляции (в
нашем примере речь идет о частотной модуляции — частотном
вибрато).
Сэмплирование — это запись образцов звучания
(сэмплов) того или иного реального музыкального инструмента.
Сэмплирование является основой волнового синтеза музыкальных звуков. Вы
уже знаете, что аппаратные или программные устройства, использующие
этот метод синтеза, называются сэмплерами.
Если при
частотно-модуляционном синтезе (FM-синтезе) новые звучания получают за
счет разнообразной обработки простейших стандартных колебаний, то
основой волнового синтеза являются заранее записанные звуки
традиционных музыкальных инструментов или звуки, сопровождающие
различные процессы в природе и технике. С сэмплами можно делать все,
что угодно. Можно оставить их такими, как есть, и сэмплер будет звучать
голосами, почти неотличимыми от голосов инструментов-первоисточников.
Можно подвергнуть сэмплы модуляции, фильтрации, воздействию эффектов и
получить самые фантастические, неземные звуки.
В принципе, сэмпл
— это не что иное, как сохраненная в памяти синтезатора
последовательность цифровых отсчетов, получившихся в результате
ана-лого-цифрового преобразования звука музыкального инструмента.
Технология, которая позволяет "привязывать" сэмплы к отдельным клавишам
или к группам клавиш MIDI-клавиатуры, называется мультисэмплингом
(Multi-Sampling). Суть данной технологии можно пояснить графически так,
как это сделано на рис. 1.14, а.
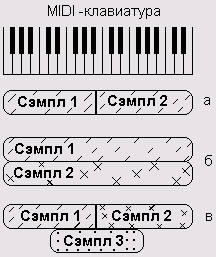
Рис. 1.14. Примеры использования технологий мультисэмплинга и многослойности
У реальных инструментов тембр зависит от высоты звука. Спектральная
характеристика звука изменяет свою форму в зависимости от частоты.
Например, у фортепиано тембр звука каждой из клавиш будет хоть немного,
но все-таки отличаться даже от своих ближайших клавиш-соседей, не
говоря уже о клавишах, расположенных предельно далеко друг от друга
— в начале и в конце клавиатуры. Если бы не существовала проблема
экономии памяти, то можно записать звучание музыкального инструмента
для каждой ноты, а полученные сэмплы привязать к каждой из клавиш
MIDI-клавиатуры. Но в этом случае для размещения звукового банка
потребуется значительный объем памяти. В принципе, такой подход может
быть реализован в программном сэмплере Gigastudio. Собственно, отсюда и
происходит приставка Giga- в названии программы: банки сэмплов могут
занимать гигабайты. Однако это не всегда оправданно, поэтому в памяти
обычно хранятся сэмплы не для каждой ноты, а лишь для некоторых. В этом
случае изменение высоты звучания достигается путем изменения скорости
воспроизведения сэмпла. Группы клавиш, для которых записываются сэмплы,
выбираются так, чтобы в пределах каждой из них вариации тембра звучания
реального инструмента были бы не заметны на слух. Это позволяет
существенно снизить затраты памяти и в то же время получить вполне
качественный, близкий к живому звук.
Для получения разных нот
сэмплы воспроизводятся с разной скоростью, при этом изменяется их длина
(время звучания сэмпла или период его циклического воспроизведения).
Нота, соответствующая воспроизведению сэмпла со штатной скоростью
(когда частота дискретизации при его воспроизведении такая же, как была
при записи), называется базовой нотой.
Если использовать малое
количество сэмплов, распределенных по MIDI-клавиатуре, то эффект
изменения длительности сэмплов будет слишком заметен. Кроме того, при
воспроизведении сэмпла со скоростью, существенно ниже той, на которой
он был записан, из него пропадают высокочастотные составляющие,
присутствующие в тембре любого (даже басового) инструмента.
Приведем простой пример. Пусть изначально сэмпл был записан для ноты до
пятой MIDI-октавы (при нумерации октав, начиная с нулевой) с частотой
дискретизации 44,1 кГц. Это значит, что для этой ноты спектр звука
потенциально может простираться до 44,1/2 = 22,05 кГц (по теореме
Найкви-ста — Котельникова). Для того чтобы получить ноту до
четвертой октавы, синтезатор должен воспроизводить этот сэмпл со
скоростью в два раза ниже той, на которой он был записан, то есть с
частотой дискретизации 22,05 кГц. По теореме Найквиста —
Котельникова: 22,05/2 = 11,025 кГц — максимальная частота
звукового сигнала. Это значит, что в спектре сигнала область частотного
диапазона размером 11,025 кГц будет, отсутствовать, т. е. спектр звука
будет ограничен в области высоких частот значением 11,025 кГц.
Чтобы свести эти неприятные эффекты к минимуму, достаточно распределения двух-трех сэмплов на октаву.
В домашних условиях попытка создать свой собственный качественный
инструмент, например, записать звучание акустической гитары, вряд ли
увенчается успехом. Для таких целей нужна лаборатория, оснащенная
специальным оборудованием. Поэтому в качестве "стандартных"
инструментов все-таки лучше использовать звуковые банки, созданные
специалистами.
Существует еще одна важная особенность
мультисэмплинга. Связав сэмплы различных инструментов с различными
группами клавиш, можно получить одновременно несколько инструментов на
одной MIDI-клавиатуре, например, для левой руки — контрабас, для
правой — флейту. Это значит, что вы можете управлять по одному
MIDI-каналу несколькими инструментами одновременно. Правда, при этом
сузятся диапазоны звучания этих инструментов, ведь MIDI-клавиш всего
128. Но этого должно хватить. Тем более что для управления
компьютерными аналогами "живых" инструментов, такими как, например,
фортепиано, используется далеко не все 128 MIDI-клавиш.
Музыкальные инструменты (условные контрабас и флейту) можно заменить на
спецэффекты, например на различные фразы, произнесенные человеком,
звуки различных природных и технических объектов.
Еще одно
понятие, связанное с сэмплерами, — многослойность
(Multi-Layering) — технология, позволяющая воспроизводить
одновременно несколько сэмплов для озвучивания одного инструмента. Как
видно на рис. 1.14, б, в данном случае "слои" — это сэмплы,
которые расположены как бы друг над другом.
Поговорим о том, как
можно использовать данную технологию. Первое, что приходит на ум,
— это возможность создания сложных, изменяющихся во времени
тембров. Многослойность можно применять для создания стереофонических
инструментов для тех сэмплеров, которые не поддерживают
стереофонические сэмплы. С помощью многослойности обойти это
ограничение просто. Если у вас имеется WAV-файл в формате 16
бит/стерео, то достаточно разделить каждый файл на два сэмпла 16
бит/моно и задействовать эти сэмплы в одном инструменте. Теперь
остается только развести сэмплы в разные стороны панорамы: сэмпл,
который раньше соответствовал левому каналу стереофонического
WAV-файла, — в предельно левое положение, а сэмпл,
соответствующий правому каналу, — в предельно правое. Кроме того,
многослойность используется обычно для более точной передачи
особенностей звучания живых инструментов в зависимости от силы нажатий
на клавиши. Нажали клавишу с одной силой — звучит один сэмпл.
Если нажать эту же клавишу с другой силой — зазвучит другой.
Пример одновременного использования технологий мультисэмплинга и
многослойности приведен на рис. 1.14, в.
Как уже говорилось, в
сэмплерах для изменения высоты тона воспроизводимых сэмплов изменяется
скорость их воспроизведения. Вроде бы все просто и понятно. Но на
практике реализовать это очень сложно. Допустим, полифония сэмплера
составляет 64 голоса — одновременно могут воспроизводиться 64
сэмпла. При этом каждый из них может воспроизводиться на своей
скорости. Но на выходе сэмплера должен быть один поток звуковых данных,
с одной фиксированной частотой дискретизации. Как объединить все
сэмплы, которые должны воспроизводиться с разными скоростями, в один
цифровой поток? Об этом вы можете прочитать в книге [12]. Как вы уже
поняли, сэмплер — устройство достаточно сложное. Современные
сэмплеры по своей сути являются неким гибридом синтезатора и
многоканального цифрового магнитофона, который может воспроизводить
сэмплы с разными скоростями. Сэмплы в этом синтезаторе используются в
качестве осцилляторов — генераторов сигналов